🌈 网友热评:实习生的成长日记
1️⃣ @生信小能手:
“实习时主导了一个代谢组与肠道菌群的关联项目,从数据清洗到发SCI只用了半年!团队协作和抗压能力直接拉满💪~”
💡 Part 4 | 行业应用:从科研到商业的价值跃迁
代谢组数据分析的实习机会遍布药企、医院、生物科技公司:
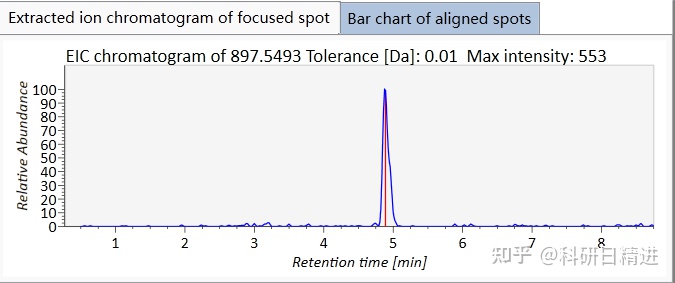
💻 Part 2 | 技能升级:硬核工具与软实力并存
核心技能清单:
1️⃣ 编程能力:SQL提取数据、Python建模(如随机森林算法2)是基本功;
2️⃣ 统计学知识:差异分析、主成分分析(PCA)、OPLS-DA模型4必须熟练掌握;
3️⃣ 跨组学整合:将代谢组与临床信息关联6,比如分析患者年龄与代谢物浓度的相关性;
4️⃣ 沟通能力:向生物学家解释数据结果,用“非技术语言”说服临床团队采纳建议🗣️。

🚀 Part 3 | 实战挑战:数据噪音与生物意义的博弈
实习中常遇到高维度、小样本数据的难题,比如如何从海量代谢物中筛选出关键标志物?答案藏在“多模态分析”中——结合机器学习(如SVM4)和网络拓扑分析,挖掘潜在关联1。数据预处理的“坑”也不少:一次实验中,因未校准质谱仪参数,导致后续模型误差放大,团队不得不返工重测🔧。
🧬 Part 1 | 实习初印象:从实验室到数据海洋
代谢组数据分析实习不仅是“实验室白大褂”的延伸,更是用代码和算法解码生命奥秘的旅程🔍。实习生需要掌握从样本处理(如质谱技术7)到数据清洗、标准化的全流程4,还要学会用Python、R语言搭建分析模型,甚至用Tableau绘制直观的代谢通路图📊。比如,某药企实习项目中,团队通过整合基因组与代谢组数据,发现了糖尿病的新生物标志物1,实习生全程参与了数据降维和可视化环节,成就感爆棚✨!

(正文完)
2️⃣ @数据炼丹师:
“第一次用深度学习预测代谢物相互作用,模型准确率超90%!老板说‘这实习生比全职还卷’😂…”
3️⃣ @未来科学家:
“在医院的实习让我看到数据的温度——一个代谢标志物帮晚期患者优化了治疗方案,那一刻觉得代码也能救人❤️🩹。”
4️⃣ @职场萌新:
“被导师逼着学完了Coursera上三门生物信息课,现在看质谱图就像看表情包一样简单🤓!”
前辈建议:“多看Nature子刊的代谢组学案例,理解生物问题比敲代码更重要!”
某实习生分享:“曾用KEGG富集分析定位到癌症代谢异常通路,导师夸我‘把数据讲成了故事’📖!”
🪄 提示:想了解更多代谢组学实战技巧?关注#生信打工人#话题,解锁隐藏福利哦~
- 药物研发:预测药物靶点,缩短研发周期(如某团队用代谢组数据优化抗癌药配方6);
- 精准医疗:为患者定制饮食方案,通过代谢物水平监测疗效2;
- 农业科技:分析作物抗逆代谢通路,培育抗旱新品种🌱。
某生物初创公司CTO透露:“我们招聘实习生时,最看重能否用数据驱动决策,而非仅会跑流程。”
🌟 代谢组数据分析实习——探索生命科学的“数据密码” 🌟
相关问答
研究生毕业生自我鉴定1000字篇一 研究生阶段,在董继扬老师的指导下主要从事核磁共振代谢组学数据处理方法的研究工作。根据课题研究的要求,有针对性的认真学习了相关的专业课程,从基础理论准备、数学知识学习、编程能力提高等方面为课题研究的打下了扎实的基础;在完成了主干专业课程学习的同时,还积极涉猎了其他相关领域的课





